One of the most fascinating developments of Large Language Models (LLMs) is their ability to call tools, meaning generating structured function calls when they realize they need external data or actions to complete a task.
Even more remarkable, this wasn't originally a feature anyone designed for. Tool calling emerged unexpectedly as a byproduct of scaling up language models.
An emergent property
The concept of emerging properties is well known in philosophy, systems theory, science, and art. Philip W. Anderson, who won the Nobel Prize in Physics in 1977, defined emergence as follows:
Emergence is when quantitative changes in a system result in qualitative changes in behavior.
The term "quantitative changes" in the context of Artificial Intelligence (AI) refers to changing the size of the model. For large language models (LLMs), this size is typically measured by the number of parameters. When we increase the number of parameters from 3 billion to 175 billion or more, we can expect new properties to emerge (GPT-4 has about 1.76 trillion parameters!).
Research by OpenAI and others (like in WebGPT and Toolformer) showed that as LLMs grew, they started to implicitly learn how to use external tools such as calculators, search engines, or APIs—just by observing how those tools were described in training data.
LLMs learned patterns like:
To get weather data, call get_weather("New York").
This ability wasn't manually engineered. It was the result of exposure to enough examples in their training corpus. Over time, the models learned not just how to generate natural language—but also how to generate the correct shape of structured calls.
There are many other emergent properties in LLMs, like Question Answering, Summarization, In-Context Learning, Coding, etc.
In this article we will focus on Tool calling (or Function calling), to learn more about other properties you can read the Emergent Abilities of Large Language Models article by Jason Wei et al. in 2022.
The tool calling feature
Recognizing the power of this emergent behavior, OpenAI formalized it in mid-2023 with the release of function calling support in its Chat Completions API.
While the original behavior emerged naturally, turning it into a reliable feature required fine-tuning and alignment.
These are some of the techniques used to refine tool calling:
- Instruction Fine-Tuning: they fine-tuned LLMs on curated examples of tool usage, reinforcing how and when to trigger a function call. This improved the model's consistency, especially in distinguishing when to generate natural language vs. structured calls.
- System Message Priming: models are given special system-level prompts that describe the tools they can access—similar to giving an assistant a toolbox and a manual before they begin work.
- Schema Enforcement: tools are described using JSON Schema, allowing the model to understand not only what functions exist but also what arguments are required and in what format.
- Reinforcement Learning from Human Feedback (RLHF): human feedback helped align the model's decision-making, making it better at choosing when to use a tool and what data to request.
- Guardrails and Delegation: the model only suggests the function call—the execution happens externally. This keeps the model secure and reduces hallucination risks.
How tool calling works
Let's focus on how tool calling works with an example. We want to extend the knowledge of an LLM with a tool, called get_weather, that is able to retrieve the real-time temperature of a city.
The process to instruct the LLM how to use this tool is formalized using a JSON structure. We need to interact with the LLM sending two requests (see diagram below):
- the first request contains the tool to be used (step 1 in the diagram);
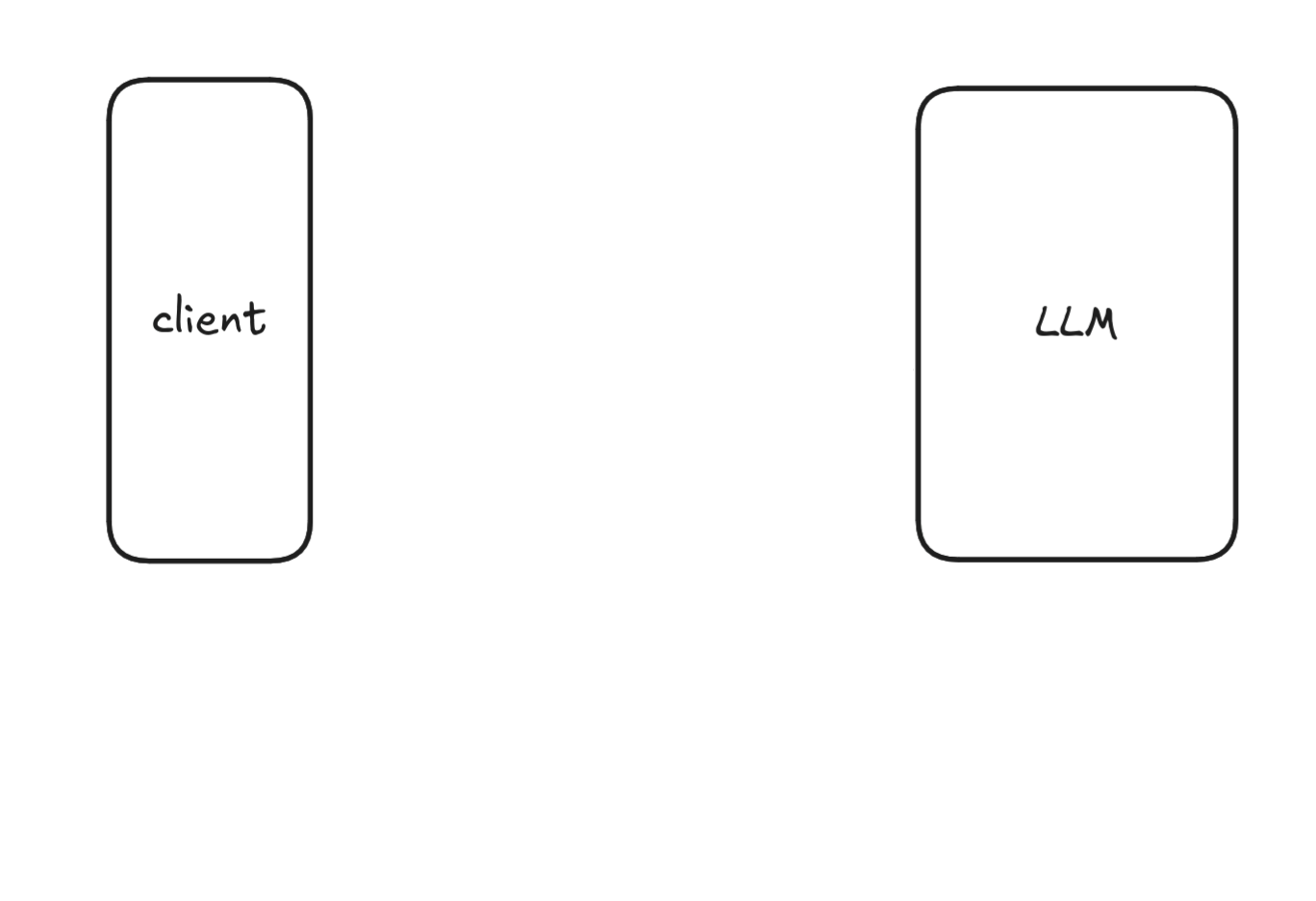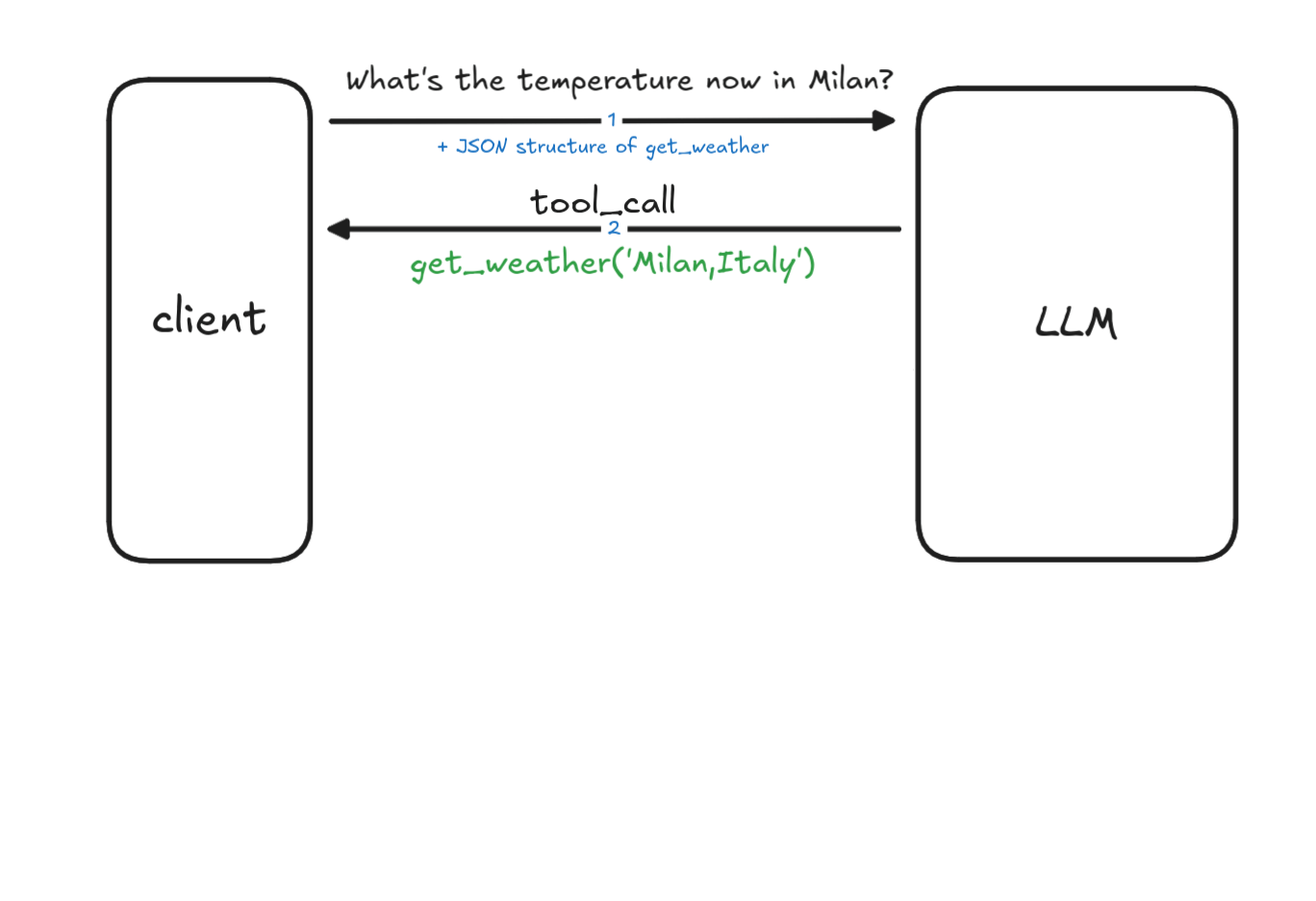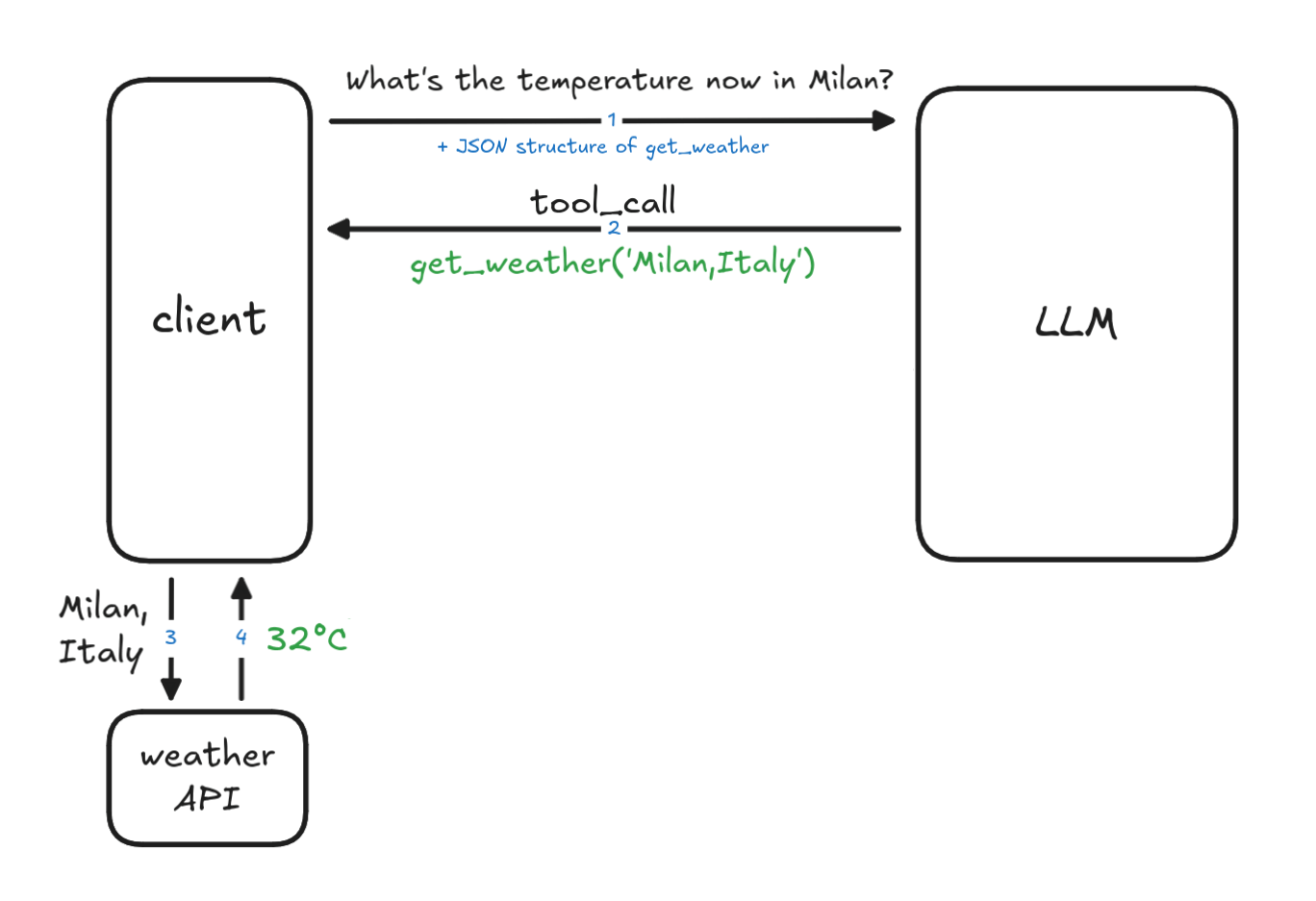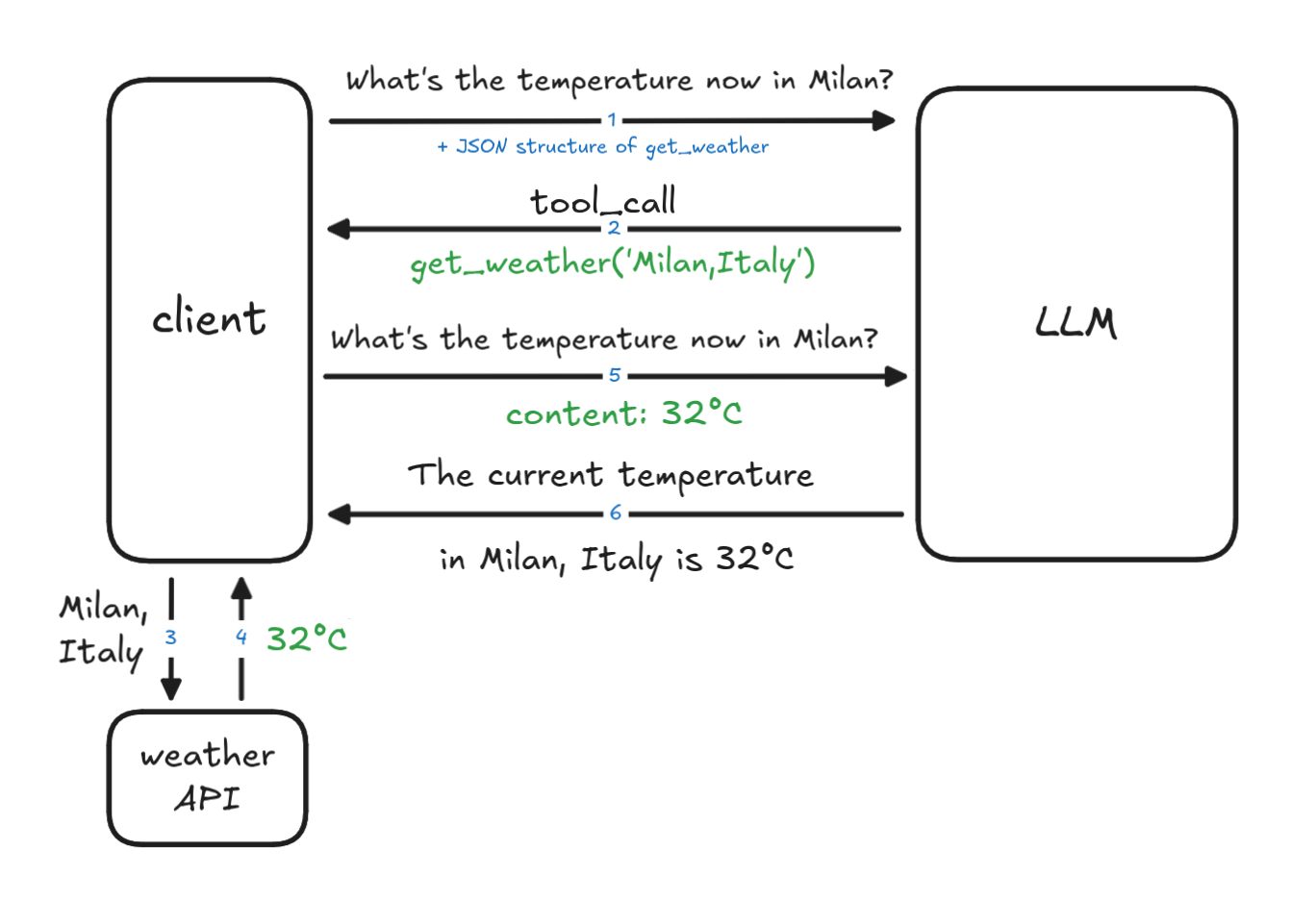
- the second request sends the content result of the tool execution (step 5).
The details of the procedure require the execution of six steps. Below, we present a diagram of these steps along with some Python code that provides further details.
Steps of the tool calling:
- We send the question What's the temperature now in Milan? with the tools specification in JSON format for the get_weather function to the LLM (in this example we use OpenAI with gpt-4o-mini)
In the tools parameter of client.chat.completions.create() function, we specify when the LLM should request the tool and how it should do so.from openai import OpenAI client = OpenAI() tools = [{ "type": "function", "function": { "name": "get_weather", "description": "Get current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "City and country e.g. Rome, Italy" } }, "required": [ "location" ], "additionalProperties": False }, "strict": True } }] messages = [{ "role": "user", "content": "What's the temperate now in Milan?" }] response = client.chat.completions.create( model="gpt-4o-mini", messages=messages, tools=tools )
The when is defined using the description of the function, which in this case is "Get current temperature for a given location."
The how is specified through the parameters property. In our case, we have only one parameter: location.
The descriptions of the function and its parameters play a critical role. If we don't use clear and accurate descriptions, the LLM may become confused and fail to trigger the function call. -
LLM replies with a function_call response; it basically recognize the need to execute the tool (function). The response contains a call_id, an identifier needed to match the function call in the next steps.
[{ "type": "function_call", "id": "fc_12345xyz", "call_id": "call_12345xyz", "name": "get_weather", "arguments": "{\"location\":\"Milan, Italy\"}" }]The LLM is able to extract the proper data for the function arguments, in this case "Milan, Italy" for the location.
-
We can extract the function parameter using the kwargs variable and passing to get_weather(**kwargs), using the arbitrary arguments feature of Python.
tool_call = response.choices[0].message.tool_calls[0] kwargs = json.loads(tool_call.function.arguments) # Execute the function content = get_weather(**kwargs) print(f"Response from get_weather(): {content}")The function get_weather() is implemented as follows (we omitted the actual API call, here you can see a real example of implementation using Open-meteo):
This step of the function execution is very important from an architectural point of view. Here we can add all the logic that we want. This part is deterministic since it is executed by a CPU and not by an LLM.import requests def get_weather(location: str)-> str: """ Get current temperature for a given location. Args: location (str): City and country e.g. Rome, Italy """ response = requests.get(f"https://someapi?location={location}") data = response.json() return f"{data['temperature']} °C"
For instance, we can insert a human feedback in the loop, check the validation of the input parameters or decide to do not execute the tool for a security reason, etc.
- The weather API responds with a simple string with the temperature in celsius degree, e.g. "32 °C"
- We resend the question + the temperature (the content) to the LLM.
# append the previous function call message messages.append(response.choices[0].message) # append result message messages.append({ "role": "tool", "tool_call_id": tool_call.id, "content": content }) response2 = client.chat.completions.create( model="gpt-4o-mini", messages=messages, tools=tools, ) print(f"Response from LLM: {response2.choices[0].message.content}") - Finally, the LLM is able to give a response to the question with the output "The current temperature in Milan, Italy is 32 °C."
Selecting the right model
If you want to use the function call feature, you need to verify whether the LLM you plan to use supports it. For example, among OpenAI models, GPT-4o performs best in this regard, including the mini version, gpt-4o-mini.
There are many other LLMs available, some of which can be run locally using tools like Ollama or LocalAI.
Be sure to check the model specifications to confirm if function calling is supported. For instance, Llama 3.2 with 1 billion parameters has not been fine-tuned for function calls.
If you want to find out which LLM performs best for function calling, you can refer to the Berkeley Function-Calling Leaderboard page.
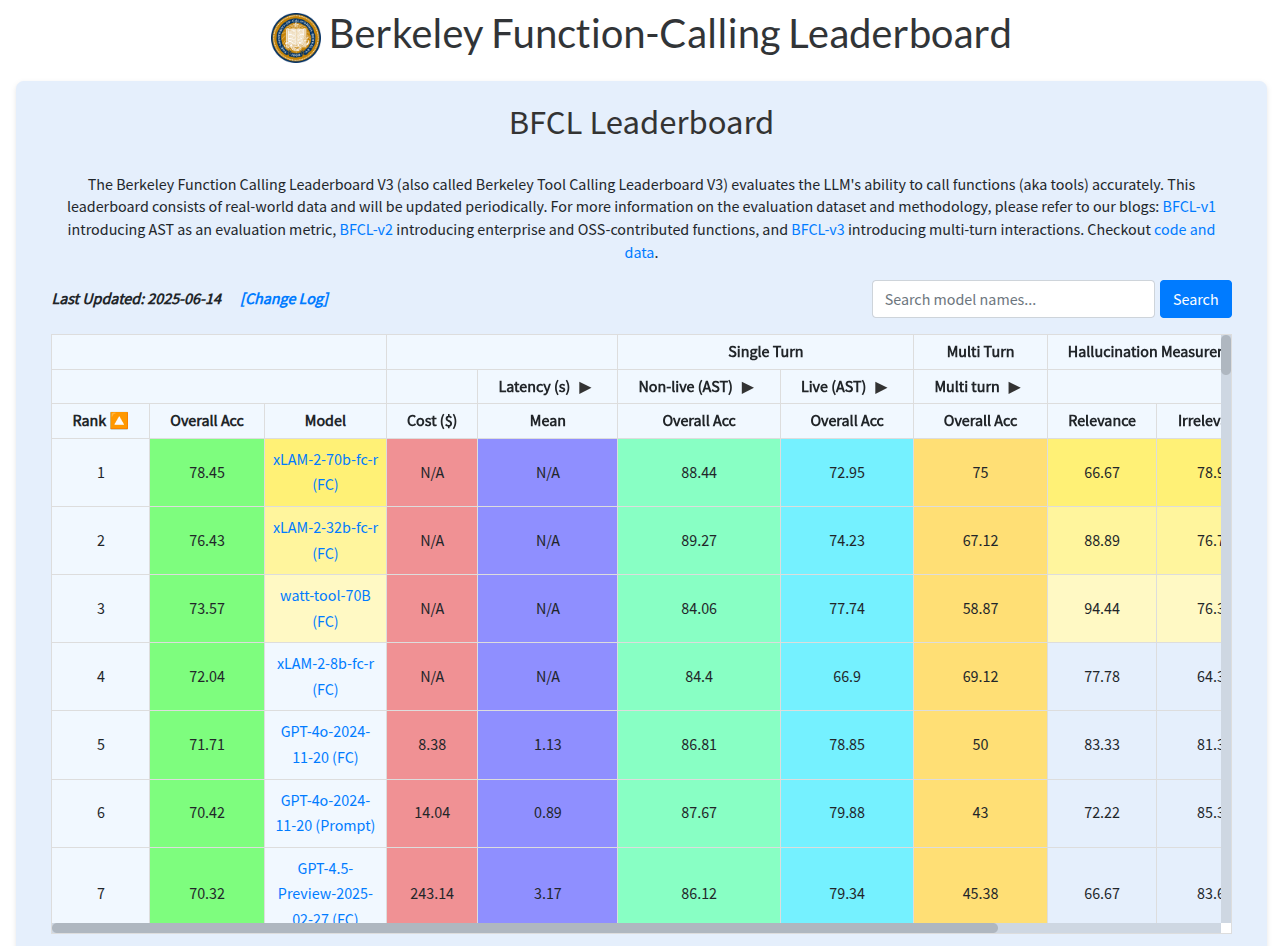
At the time of writing this article, the best LLM for function-calling is xLAM-2 at 70B with an overall accuracy of 78.45% (GPT-4o is around 71%). xLAM is a family of Large Action Models based on Llama and developed by Salesforce.
Moreover, selecting the right model also involves considering resource usage. If we want to deploy Agentic AI systems in production, we cannot expect to run every workflow using a Large Language Model (LLM).
There are two main problems with this approach:
- high resource consumption;
- latency in response time.
Today, LLMs consume significant resources, and an Agentic AI system multiplies this usage by 4 to 15 times the tokens used in a single LLM interaction.
Regarding latency, the issue is even more evident: we cannot expect Agentic AI systems to provide answers in tens of seconds when responses are needed within milliseconds.
These points were highlighted in a recent article Small Language Models are the Future of Agentic AI by Peter Belcak et al. from NVIDIA Research.
A Gateway to Autonomous AI
Today, tool calling powers everything from simple weather bots to fully autonomous agents that can reason, act, and interact with APIs in loops. It's the cornerstone of systems like:
- Agentic AI, e.g. assistants that book flights, summarize PDFs, or automate workflows;
- Multi-agent ecosystems, collaborating models that divide and conquer tasks;
- Context-aware applications using standards like the Model Context Protocol (MCP).
Conclusion
Tool calling started as a surprise. No one explicitly programmed it. But like many of the most powerful features in modern AI, it emerged—and was then refined into a reliable, developer-friendly capability through fine-tuning and structured integration.
As tool calling continues to evolve, it blurs the line between language understanding and software execution—transforming LLMs from chatbots into autonomous digital workers.